AICYC is pronounced: (“A /eɪ/ I /aɪ/ CYC /saɪk/”)

Meet SAM your personal knowledge guide. SAM is a semantic AI model that knows billions of facts and topics. AICYC is the encyclopedia of the future. The video below (56s) shows that learning is in the discovery journey not in what you already know.
The best way to understand AICYC is to watch SAM at work guiding users to explore new topics without having to enter words.
At the end of the discovery journey AICYC uses generative AI to create multimedia encyclopedic articles called knowledge clips. The AICYC project is building the encyclopedia of the future to restore the ability for anyone to brouse and extend their knowledge by thinking outside the prompt box.
AICYC IS A NEW WAY TO KNOW.
The AICYC team needs your understanding and support to make real what was an impossible dream only a few years ago: a vast knowledge commons where everyone can explore and learn. The technology behind SAM is mature and ready to go. We need your help in establishing the legal and social foundation to bypass the rich and powerful that have monopolized access to knowedge. AICYC is as much a cause as a means.
MANIFESTO

Humans use knowledge in the form of concepts, context and facts to communicate understanding and take actions as a group and for individual curiosity or educational growth. For the past 25 years keyword search technology has dominated access to information while blocking access to new ideas or topics outside the user’s knowledge. Users are steered to content by algorithms that cannot understand meaning. This is the prmary source of knowledge polution on the internet today. When knowledge is polluted by misinformation, disinformation, hate, propaganda, conspiracy theories or factual errors the exchange of information is threatened. We believe access to clean knowledge is a common good that must be protected for all internet users. For the first time in human history access to knowledge can be democratized, decentralized and made immutable for the common good.

To build AICYC using generative AI to write and illustrate articles of interest to every user in every language. Each article, called a knowledge clip, is referenced by authoritative sources and automatically fact checked by a semantic AI model (SAM.) Users can discover knowledge by exploring subject areas of interest. Something current AI can not easily do.

A world wide web where information flows freely, not dammed up by algorithms or diverted to private channels for profit. An internet where knowledge owners and creators are rewarded for sharing their work. A world where big money or propagandists can not pollute knowledge by diverting cesspools of hate or propaganda into the knowledge stream. A place where children can safely learn and explore knowledge guided by curiosity not opaque words.
The single most damaging effect of the text box has been the insidious claim that there is nothing better. An antitrust trial has convicted the leading search engine of using its dominant market position to monopolize text-based search. Similar financial interests are driving generative AI efforts to make the prompt box the only way to use their product. The text box and the prompt-based user interface are doing massive harm by rigidly enforcing a knowledge apartheid based on literacy. The top 2% wealthiest families control access to nearly all text-based algorithms, keeping everyone in the world locked within their literacy bubble. Like the dwellers in Plato’s Cave, every literacy class is content with the flickering light reflecting off their knowledge bubble. The most literate resist leaving their bubble because their intelligence is confirmed by search or LLM results. However the most literate 2% with 50,000 word vocabularies can only access 5-10% of LLM responses. The AICYC project aims to help the 3 to 4 billion people with smartphones with limited or no access to new knowledge in any language to increase their literacy and understanding not repress it.

Generative AI large language models (LLM) create well written content in response to natural language prompts. LLM also misinforms and misleads users seeking factual responses. LLM obscures the source of the creative content it uses.
Our concerns are about the practical problem of accessing and keeping knowledge clean for everyone who wants to use generative AI to learn and discover.
We are concerned that factual errors over time will be recycled into training data creating a vicious circle, polluting knowledge content with bias and factual errors. Some think the AI pollution problem can be fixed by spending billions of dollars of computing power to do more of what has been done before. We don’t.
We are concerned that neither big tech or big government can fix AI. Big tech is too invested in a single technology to look elesewhere for a solution. Governments are listening to the vested interests of business.
We are concerned that generative AI can’t read or understand what it writes. The transformer statistical process used to generate written articles does not understand the concepts, context and common sense facts humans use to read. This is a deep flaw that can not be erased by more computing power, new statistical algorithms or by regulation.
We are concerned about knowledge gaps that limit access to information. Everyone is disadvantaged by information access that requires knowledge to gain knowledge. Current keyword based information technology profoundly limits information discovery to those areas the user already knows. This creates a unique knowledge bubble for every user. Those with curiosity about something new are limited when they don’t know relevant words, context or concepts to use in keyword search or as generative AI prompts.
We are concerned that creators and underwriters of content are not benefiting from AI and their contributions to training generative AI are being ignored or plagarized. And unrewarded.
We are concerned that attempts to regulate AI risk through government actions will favor failed technologies and big tech investors through regulatory capture.
We are very concerned about ‘jailbreaking’ using text prompts that override a chatbot’s safety restrictions and ‘prompt injection’ where a user creates an input or a prompt that is designed to make generative AI behave in an unintended manner.
We are not concerned about dystopian future stories featuring generative AI because we know a solution exists.

“I have a dream of a semantic AI in which computers know the concepts humans use to understand and reason with.” Sir Timothy John Berners-Lee OM KBE– Inventor of Web 1.0, the World Wide Web.
BACKGROUND
Our solution is a semantic AI model (SAM). SAM follows the semantic AI standard protocol W3C RDF devised by Berners-Lee found here. This standard is also known as Web 3.0 or the Semantic Web. (not to be confused with Web3 described below). The semantic web standard also provides a machine to machine interface to interact with AI agents. Just as humans will go to AICYC for safe knowledge so will AI.
SAM is not an alternative to the large language model (LLM) used in text generative AI. It is complementary and the missing component of artificial general intelligence (AGI). Just as humans read and write so must intelligent machines. Current AI only writes. No matter how well it writes, or how much better it’s writing gets, LLM only writes. SAM reads and understands.The two modes of AI, LLM and SAM, join together to create the AICYC.
The concepts humans use to fact check are very specific and detailed. They are not words in text they are concepts in mind. For SAM to fact check generative AI it has to have knowledge across every domain and context. Its vocabulary must be like that of an expert in every domain. Not only in academic topics but in every topic from Anime to Zoonoses. Unlike human experts that know a few knowledge fields in detail, SAM covers every interest across all knowledge domains.
SAM updates and increases its knowledge by reading new material it encounters. SAM is not trained by transformer neural net or machine learning. SAM uses natural language process (NLP) to mine nuggets of knowledge inside the world’s online content.
SAM is used to automate steering and alignment prompts to guide the large language model (LLM) to write on-topic encyclopedia articles. All decisions SAM makes are transparent and there is no hidden or opaque code. An example of an AICYC article about Sphynix cats (the one in the video) describes how SAM works to correct LLM hallucinations.( here).
TECHNOLOGY
The graphic below shows a single knowledge node in SAM’s knowledge graph. There are millions. The example shown is the engineering concept “Analog signal.” This illustrates the complexity and diversity required to add human reasoning and understanding to AI. SAM’s vast tree of knowledge has billions of contextual pathways connecting millions of concept nodes connected to form common sense facts. The parent node in the Taxonomy “Analog circuits” has over a hundred concepts under it.
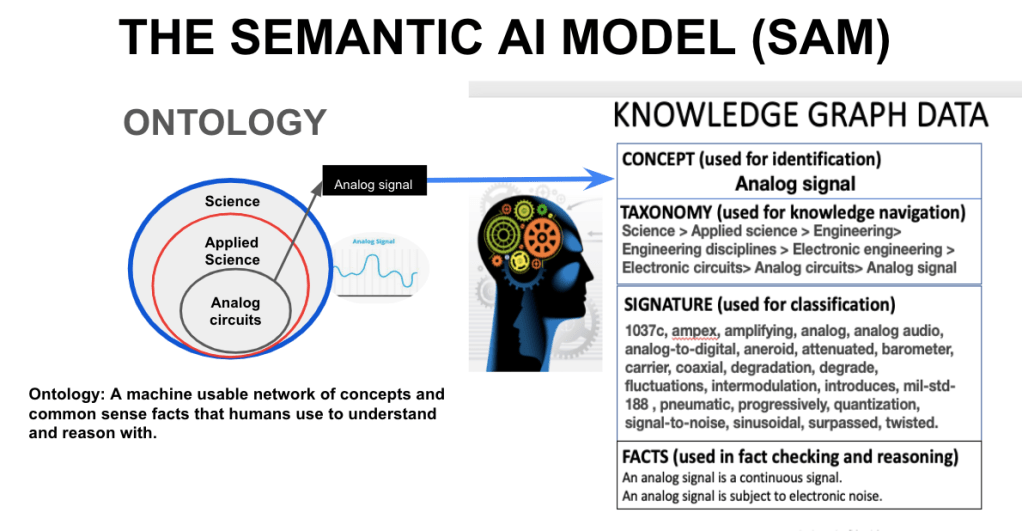
The AICYC uses the knowledge graph data to steer and align large language models (LLMs) to generate AICYC encyclopedia articles.
SAM has read billions of web pages creating a knowledge directory of the entire world wide web. We use the same documents such as Common Crawl (described here) that are used to train LLM.
More broadly SAM guides the user of AICYC to explore the web as an alternative to search engines. In many cases the search for website links is redundant.
GLOBALIZATION
AICYC is a multi-lingual knowledge commons that promotes greater understanding and informed decision making by its users, while encouraging social interactions based on interests.
Global knowledge access in the language of the user is central to getting clean knowledge distributed without government or for-profit control or interference. LLM writes articles based on native language prompts. SAM operates in 33 languages covering 7 billion potential users that do not have English as a first or second language. Interests are language independent and SAM guides users to their interests using universal pictures and icons. An example in Greek, German and Chinese can be found here.
IMMUTABILITY
SAM is a seed bank that stores knowledge in a blockchain ledger . To prevent contamination, knowledge is made immutable and access to facts are decentralized and permissionless. SAM can check sources against blockchain master nodes for signs of vandalism or changes in source content.
DECENTRALIZATION
A distributed autonomous organization (DAO) governed by an independent community uses smart contracts to implement AICYC operation and policy regarding decentralized content access.
A Right To Know (RTK) manifesto will set out the terms of use, and policy to be implemented and approved by the DAO community. The AICYC DAO charter will not be subject to centralized control or change in control by private or government organizations.
The DAO governing body will have access to the data, software and algorithms behind the AICYC to certify integrity and approve changes of the open-source version. One model for the organization of the AICYC is the Wikimedia Foundation. More about AICYC governance and the fat protocol operatiing platform can be found here.
WHERE DID ALL THE SAMS GO?
It is difficult to grasp how hard it is to code human knowledge for machine use. The AICYC project team considered other possible solutions to the clean knowledge problem in hopes of adding to our solution.
There were two very well funded attempts at building SAMs in the past: Cycorp’s CYC and IBM’s Watson. Here is the story about where these SAMs went.
CYC
CYC was started over 40 years ago by a noted AI scientist Douglas Lenat. In 1977 he was recognized for his machine-learning program AM (Automated Mathematician)which used symbolic reasoning to discover mathematical concepts. In 1984, Dr. Lenat started his CYC project with the goal of constructing a SAM that understood common-sense facts across all human knowledge domains. This work continued under the company Cycorp until it ended last year.
CYC eventually contained 25 million rules using 2,000 human years to manually code knowledge. The cost exceeded $100 million and ended after 45 years.
In additon to the cost of human ontology engineering the CYC project was a 1st order logical system that required many more rules to operate than a 2nd order system like SAM. CYC could not use rules like “All Musicians play at least one musical instrument.” Instead it could only express specific facts like “Eric Clapton plays guitar.” These rules were manually added. By comparison SAM can bypass writing hundreds of millions of first order rules and automaticall extracts facts as fact assertions.
The name AICYC was chosen to designate using AI to build a CYC. CYC was a great and noble human effort but was not completed. Douglas Lenat died in August 2023 at the age of 72.
IBM Watson-HEALTH
While very well known for its Jeopardy brand, Watson was a SAM that had a deep knowledge base centered on health sciences. After a decade using over 20,000 human years at a labor cost exceeding $1 billion Watson-Health was discontinued. One doctor involved in testing said Watson did not cover knowledge in sufficent depth.to manage patient records.
Both these projects and many others failed because their knowledge base was too limited to cover the general knowledge required to meet human needs for accurate information about their interests no matter what that is.
AICYC PROJECT STATUS
OPEN SOURCE API
Two sponsoring companies, Intellisophic and iKNOWit, are contributing the SAM code stack and knowledge graph data to the AICYC project. This includes a stable well tested application programming interface (API) which has allowed the AICYC project team to build the encyclopedia foundation quickly at low cost. Access rights to the API are granted under GNU open-source or similar license.
FUNDING
To avoid big tech capture the project will limit startup funding to individuals or independent charitable organizations that agree with the Right To Know (RTK) operating principles. Initial funding is to be used to:
- Pay for crowd sourcing and grant writing expenses.
- Create a legal charter for a charitable 501(c)(3) called AICYC DAO LLC.
- Create a devOps environment like GitLab to provide API access for the AICYC project community to build a public access demonstration website.
The AICYC project will seek crowd sourced contributions, educational grants and volunteer services to startup. AICYC will be ad free and personal information including usage data will not be tracked or sold. The creators of the technology are dedicated builders of stable software solutions on a global scale.
THE LLM IS TO BE DETERMINED
A variety of large language model AI including chatGPT, Claude, Pi, Gemini, Mistral and Llama are being tested.
Video and art to illustrate the LLM articles will also be open-source where possible. Even the logo of SAM reading was created by a generative AI called DALL-E2.

OUR SPONSORS
Intellisophic

Intellisophic has provided semantic data and software to the information industry for nearly 25 years. Intellisophic owns one of the largest private knowledge graph taxonomies in the world. The Intellisophic stack is called DeepMeaning AITM with millions of lines of code used to mine knowledge in text documents. Learn more here.
iKNOWit.WORLD

iKNOWit is a startup using SAM to build a social media meeting place that networks users based on interests. iKNOWit licenses the SAM technology from Intellisophic. More information including a video demonstration of the semantic AI user experience and meeting place purpose can be found at the iKNOWit website here.
iKNOWit, Inc is a Wyoming C corporation. Wyoming is one of only three states that allow the formation of a DAO as a limited liability company (LLC).
SAM’s CREATORS
HUGH DUBBERLY

THE KNOWLEDGE NAVIGATOR
Hugh was the head of Apple Creative Services when he wrote and created the Knowledge Navigator video for John Sculley, Apple CEO. That video predicted many of the internet features we know today including SIRI and iPhones. The semantic AI model used to guide AICYC can be traced back to Hugh’s vision. Learn more about how Hugh started SAM’s story here.
The Dubberly Design Office (DDO) created SAM’s user experience (UX) that is central to AICYC. The video at the start of our story shows how Hugh’s UX guides users to topics of interest. (< 2 min.). Selecting a topic like Sphynix Cats will generate an annotated encyclopedic article written by an LLM.
ROBERT FAUGHT

MOBILE DESIGN MASTER
Mobile is the most common mode for information delivery on the internet. Our MUX designer Robert Faught appears in SAM’s story in his role as a master of mobile design and as a developer of precursor to SAM’s 2nd order inference engine. Rob completed graduate studies at MIT’s Visible Language Workshop (later a part of the MIT Media Lab headed by Nicholas Negraponte.)
CHRIS DANCY (They,Them)

THE MINDFUL CYBORG
Chris is known as “the most connected man on earth.” He is leading the charge of humans into the cyborg world using AI to improve personal health and mental well being. Connecting to clean knowledge is a critical part of the wellness experience especially for young social media users. Learn more about Chris here.
Chris Dancy, is the CEO of iKNOWit, and leading the AICYC fund raising effort.
MIKE HOEY (He,Him)

MASTER OF BIG DATA DEVOPS
Mike has led the development and operations of DeepMeaning AI since its beginning. He is the owner of iKNOWit’s outsource team Source Meridian and a founder of both Intellisophic and iKNOWit.
Before building the DeepMeaning AI solution Mike led the development of one of the largest software publishing platforms ever built called LIQUENT InSight®. InSight is used to publish and manage the largest documents in existence and covers every electronic print format. Mike used his skills to handle all document variants from OCR to HTTP needed to extract knowledge from billions of websites and private publisher document repositories.
Mike is a master of big data cloud computing. He has led the DevOps for SAM’s foundation code and designed the API used to connect SAM to AICYC application development. His graduate degrees are in computational AI from Syracuse University.
DR. HENRY KON (He, Him)

THE AUTOMATOR OF SEMANTIC AI
Henry has served as Chief Scientist of Intellisophic from the beginning. Henry is a co-inventor of the Orthogonal Corpus Indexing (OCI) technology used to extract taxonomies from published reference works that made scale feasible. The OCI patent can be found here. It is one of the most cited in the field of semantic AI. The OCI invention increased the rate of knowledge extraction from text a hundred fold. This invention made SAM possible.
In 2005 Henry and Mike presented a seminal article “Leveraging collective knowledge” describing the automation and purpose of the OCI process at the 14th ACM international conference on information and knowledge management in 2005. The article can be found here.
Henry holds a Ph.D. in Management and Computer Science (MIT) specializing in semantic knowledge representation.
DR. VOLKER KUEBLER (He, Him)

THE WEB3 MASTER
Volker led Intellisophic for six years as COO/co-CEO. He worked to incorporate blockchain Web3 features into the SAM platform. The operating design for SAM’s eco-system can be found here. Volker was instrumental in positioning SAM as a fat protocol operating platform, adding utility and private tokens to reward creators and investors, and using smart contracts and DAO to make knowledge ownership immutable and decentralized. His greatest concern was transaction scalability and security that was crucial to SAM and the AICYC promise of a clean knowledge source.
Dr. Kubler is currently the CEO of Hathor Network that created a highly scalable distributed ledger suitable for SAM Web3 use.
Volker is an accomplished mountain climber and Olympic gymnast. His climbs include K2 in the Himalayas and many others.
Volker holds an MBA from the University of Chicago, and a Ph.D. from the University of Heidelberg.
CATHERINE BRANSCOME-MORRISSEY (She, Her)

CHILDREN’S CONTENT SAFETY OFFICER
Catherine is the founder and president of Branscome International, a global licensor of kid and family entertainment-driven products since 2001.
Company activities range from acquiring and licensing media content to executive production and tech/media consulting. Catherine specializes in content creation for Kids and Family audiences. Past clients include traditonal outlets such as Disney, Cartoon Network, Sony and Nickelodeon, as well as online powerhouses such as worldwide YouTube and influencers.
The AICYC project is committed to child-safe knowledge access. Catherine will help design the Right To Know (RTK) guidlines for children’s use of AICYC. Her knowledge of specific country standards for children’s entertainment is an essential part of AICYC smart contract design and RTK policy.
Catherine has been a key team member consulting in the development of the SAM experience for children and female audiences since its inception.
GEORGE BURCH (He, Him)

THE OG OF SEMANTIC AI
In 1964 George was assigned to Project MAC (Machine Assisted Computation) by the Office of Naval Research (ONR). George was employed by MIT. On the MAC team were the great grandfathers of AI: Dr. John McCarthy and Prof. Marvin Minsky. The inventor of the first chatbot Eliza, Dr. Weizenbaum, was also on the MAC team. George learned the mathematical foundations of semantic AI and generative AI then.
In 1965 George received the Military Operations Research Society (MORS) prize for solving an operations reseach problem using Lisp.

In the 1970s George developed the technology used to geocode and map the United States. His contributions were algorithms that automated human digitizing by converting raster (pixel) data to machine recognizable objects (vectors). George used Fortran to build a lisp compiler. The machine was used to digitize the entire US waterway system for the Environmental Protection Agency.
George led the automation of the US Post Office in the 1980s contracted to Booz-Allen. It was one of the earliest industrial scale projects using that the C language. George worked with Dr Roger Shank, a noted AI theorist, to build an interactive kiosk that served post office customers across the US. The kiosks were the first large scale public use of AI assistants.
In the 1990s George was known as the Data Doctor for his work curing errors in relational data systems. He founded Vality Technology with Robert Faught, SAM’s mobile design master, and led the development of the data quality product “Integrity” that formed the foundation for the Extract Transform Load (ETL) data integration industry. The Integrity product is now part of IBM’s infoSphere DataStage product suite.
George and Robert built a second order logic inference engine called Axion to manage and maintain computer code. That experience has been used to design SAM’s reasoning engine.
George, Mike and Henry founded Intellisophic in 1996 with the mission to turn human knowledge into machine useable data. George and Henry are co-inventors of the Orthogonal Corpus Indexing (OCI) technology. The OCI patent is US7720799B2 . The patent is one of the most cited in the field of Semmatic AI. It was filed with the Patent office in 1997 and granted in 2010 making it the first description of a method called DeepMeaningAITM for automatically constructing a semantic AI model.
When 9/11 occured Itellisophic worked with natonal security agencies to build a knowledge graph with tens of thousands of concepts terrorists might use to organize an attack on the United States. The problem today is the same: identifying bad actors that use LLM to plan attcks. George was awarded the Senatorial Medal of Freedom for his 9/11 service.
George graduated from the United States Airforce Academy in its first graduating class in 1959.
His advanced degrees are from Johns Hopkins University in Operations Research and Statistics. Prof. Geoffrey Watson, inventor of the Durbin-Watson theory, was his thesis advisor.
George is a zen master (Roshi) and the founding abbot of the zen buddhist temple at the US Air Force Academy.
George will manage the AICYC project until a DAO governing body is established. He has used LLM extensively to write articles posted on AICYC.
George can be reached at george@aicyc.org or through the message form below.
IN MEMORIUM
DR. JOHN PALMER

Dr. Palmer is the inventor of the 8087 co-processor. His work at Intel provided the foundation of current special purpose chip sets like Nvidia that powers generative AI today. John built the first parallel processing chip for his company nCUBE and later joined Danny Hillis at Thinking Machines and then at Applied Minds where the Google Knowledge Graph product was invented.
John worked with Rob, George and Henry in developing the AXION inference engine. His death in December 2017 was unexpected. He is very missed and we are dedicating the AICYC encyclopedia article on the Intel 8087 found here in tribute to his genius and decades long friendship.
JOIN US
Please let us know your interest, suggestions and comments regarding the AICYC Project. Scroll down past the form to see the current blogs for more details.


(c) 2023-2024 iKNOWit, Inc. This content is protected under copyright law. All rights reserved..
